Push-button, full-stack prototypes are finally here. And we don’t require a proprietary low code platform like other vendors. Splicer deploys right to the standard enterprise stack you are already running.
Introduction
In this post, I will use Splicer tooling to cherry-pick client elements from server data as demonstrated our native low code video.
Developers often kick off projects by finding and then adapting open source sample code. But what if that sample included your specific data model? Key to this process is a simple mechanism where we create our “meta model”. This is a object data model that is defined at a meta layer so that we can apply it to both server and clients. That process is very simple as outlined below.
With the advent of microservices, each application can have its own API. So we will create a “meta model” for a mobile app and its associated microservice API. Also, we can either tap into an existing relational database or define our own. Even though web and mobile apps might share a common database schema, the user experience and “payload” requirements are typically very different. This is a primary reason we recommend creating a separate API for mobile.
These techniques are intended for full stack, enterprise development – meaning we will create native, low code mobile apps, Angular or React websites, and associated Spring Boot microserivces.
Low Code Workflow
What does the meta model workflow look like? First, Splicer lets us tap into existing relational data. For our demo, we start with the MySQL Sakila sample database1. The first step is to pick data elements for our native mobile app. We use the CAM editor for our cherry-picking. In the screenshot, the available server database structures is on the right-hand-side; we drag-and-drop elements over to the left-hand-side to define our client models. In the example below, we show adding a “Customer” (user) perspective to the already-defined Actor perspective.
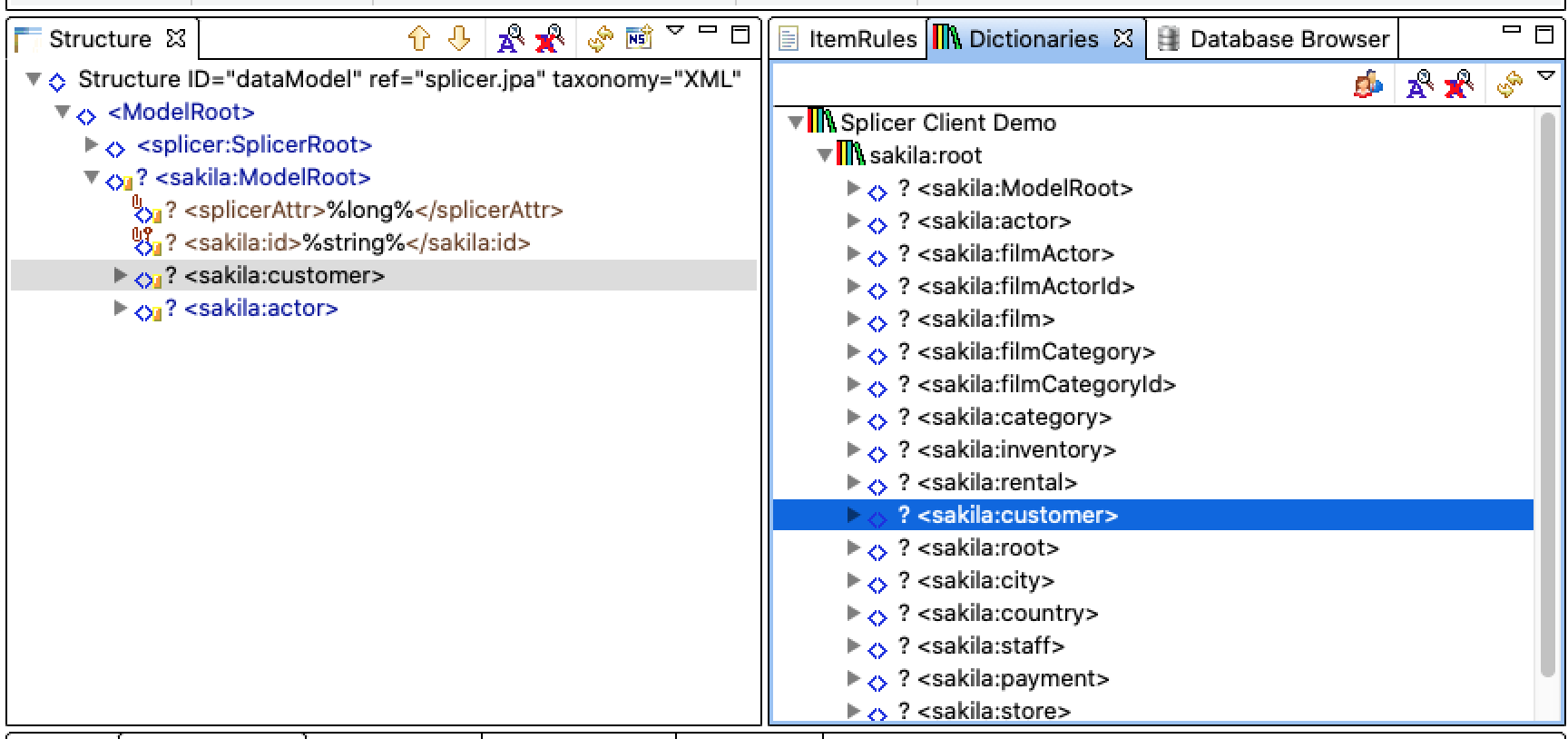
Now, when we run the generated iPhone (IOS) app, we see the two root objects.
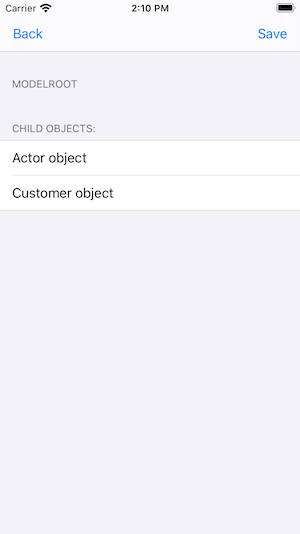
As we click on the Customer object, we navigate through all of its child screens in the following order: Customer -> Store -> Staff.
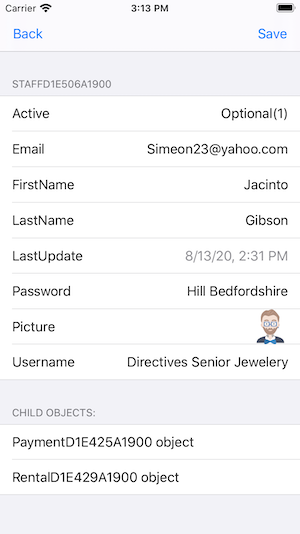
Now that we’ve arrived at the edit Staff form, we see various element types that are editable including photos. As demonstrated our native low code video, we can select a different photo and then click “save” to upload it along with the other edited data to the server. We have found this simple, object-perspective-based, MDD mechanism is sufficient to fulfill most mobile use cases.
Also, below, we see the various controls themselves are automatically typed. Below is a time editor for the LastUpdate field:
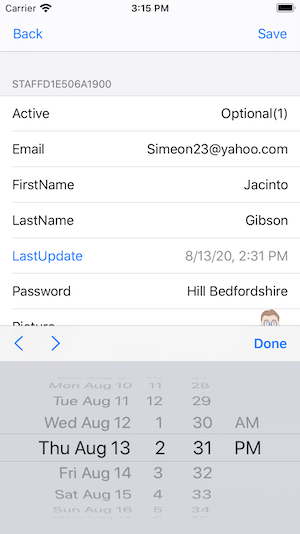
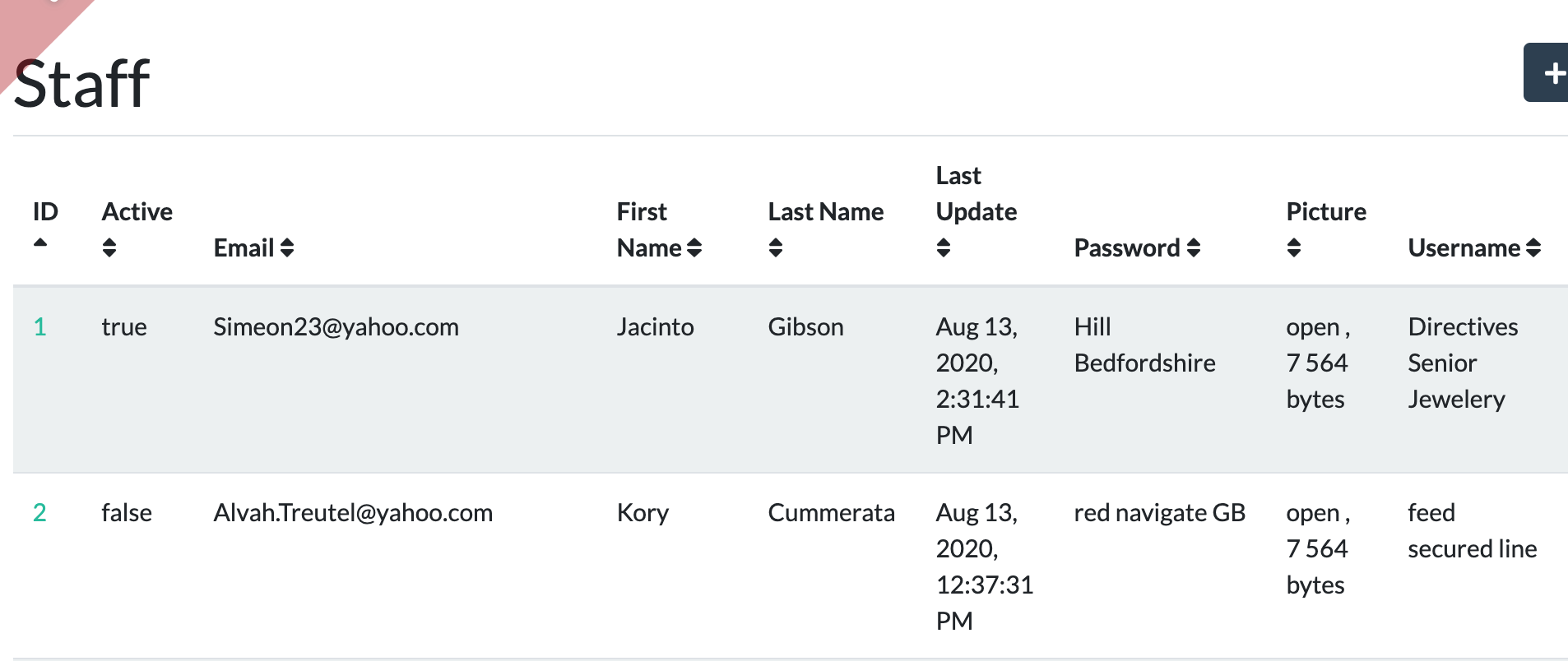
And the following Angular or React forms are also generated. Here is the Staff listing form showing the same data. Other forms are also included to view, edit, and delete individual objects.
The entire enterprise stack shown here is 100% generated, native code - hence “native low code”. The native mobile clients use the modern MVVM design pattern in Swift for IOS, and also Java for Android. And the system is backed by generated, cloud native, Spring Boot microservice code including API/swagger, Spring repositories, typesafe Hibernate models, HazelCast, miscellaneous controller code, sample data, unit tests, and “cloud native” Docker/AWS/ECS/Kubernates integration.
End-To-End Typesafety: Splicer extends typesafe entity classes out to compiled mobile clients. To summarize, models are defined in CAM, Splicer synchronizes this meta model with client and server model artifacts, and then various compilers enforce those definitions.
Benefits
Hiring:
A major benefit of this approach is hiring. Besides delivering a first cut of your application at a record pace, we make hiring much easier –- allowing developers to specialize generally around View and ViewModel coding. And because we recommend generating native clients, these factors reduce the number of skill sets required. This opens up the candidate pool, and reduces cost per dev.
Benefit Highlights
• Kickstart projects smoothly
• Prototype at a fraction of the time and cost
• Free up senior staff
• Tap into existing data
• Deploy to your existing, open source stack
• No runtime fees
• No special coding skills required - developers can code as usual
• Pick from a variety of standard clients
• Coordinate distributed teams more easily
• Better security as no dependence on external systems
• Easier maintenance via typesafe, Agile data structures
• Complementary to an overall digital transformation strategy
The Native Low Code Advantage
Develop at the pace of low code, but deploy to your own stack. That is the advantage of native low code.
If this interests you, feel free to email us at info@splicer.io with a bit of information about your project. In most cases, we can demonstrate a working prototype of your data model at no cost.